Comodines de Windows y expresiones regulares de Windows
Comodines de Windows le permite especificar un archivo o grupo de archivos escribiendo un nombre de archivo parcial. Se escanea el directorio apropiado para encontrar todos los archivos que coincidan con el nombre parcial. También puedes usar expresiones regulares para especificar archivos al usar TCC (vea abajo).
Generalmente se utilizan comodines para especificar qué archivos tienes ser procesado por un comando. Si necesita especificar qué archivos deben no ser procesado, ver Rangos de exclusión de archivos (solo para TCC comandos internos), o EXCEPTO (para comandos externos).
La mayoría de los comandos internos en TCC o CMD aceptan nombres de archivos con comodines en cualquier lugar donde se pueda usar un nombre de archivo completo. Hay dos caracteres comodín, el asterisco * y el signo de interrogación ?. Además, en TCC puede especificar un conjunto de caracteres (ver más abajo).
ADVERTENCIA: Cuando utiliza un comodín para buscar archivos para procesar en un comando como PARA or DOy crea nuevos nombres de archivos (ya sea cambiando el nombre de archivos existentes o creando archivos nuevos), los nuevos nombres de archivos pueden coincidir con su comodín de selección y provocar que los procese nuevamente.
Asterisco * comodín
An asterisco * en una especificación de archivo significa "un conjunto de caracteres o ningún carácter en esta posición". Por ejemplo, el siguiente comando mostrará una lista de todos los archivos (incluidos los directorios, pero excluyendo aquellos archivos y directorios con al menos uno de los atributos oculto y te) en el directorio actual:
dirección *
Si desea ver todos los archivos con un .TXT extensión:
dir * .txt
Si sabes que el archivo que estás buscando tiene un nombre base que comienza con ST y una extensión que comienza con .D, puedes encontrarlo de esta manera. Nombres de archivos como ESTADO.DAT, STEVEN.DOC, y ETS Se mostrará todo:
dir st*.d*
TCC También le permite usar el asterisco para hacer coincidir nombres de archivos con letras específicas en algún lugar dentro del nombre. El siguiente ejemplo mostrará cualquier archivo con una .TXT extensión que tiene las letras AM juntos en cualquier lugar dentro de su nombre base. Por ejemplo, mostrará AMPLE.TXT, SELLO.TXT, CLAM.TXTy AM.TXT, pero lo ignorará RECLAMACIÓN.TXT:
directorio *soy*.txt
¿Signo de interrogación? comodín
A signo de interrogación ? coincide con cualquier carácter de nombre de archivo. Puede colocar el signo de interrogación en cualquier parte del nombre de un archivo y utilizar tantos signos de interrogación como necesite. El siguiente ejemplo mostrará archivos con nombres como CARTA.DOC, ÚLTIMO.DAT, y CAMADA.DU:
dir l?tter.d??
El uso de un comodín de asterisco antes de otros caracteres, y de los rangos de caracteres que se analizan a continuación, son mejoras a la sintaxis estándar de comodines de Microsoft y no es probable que funcionen correctamente con software que no sea TCC.
Los signos de interrogación "extra" en su especificación comodín se ignoran si el nombre del archivo es más corto que la especificación comodín. Por ejemplo, si tiene archivos llamados CARTA.DOC, CARTA1.DOCy LETRA.DOC, este comando mostrará los tres nombres:
carta de directorio?.doc
El archivo CARTA.DOC se incluye en la pantalla porque el signo de interrogación "adicional" al final del ¿CARTA? se ignora cuando coincide con el nombre más corto CARTA.
Comodines del juego de caracteres
En algunos casos, el ? El comodín puede ser demasiado general. TCC (pero no CMD) También le permite especificar el conjunto exacto de caracteres que desea aceptar (o excluir) en una posición particular en el nombre del archivo usando corchetes. []. Dentro de los corchetes, puede colocar los caracteres individuales aceptables o los rangos de caracteres. Por ejemplo, si quisieras hacer coincidir CARTA0.DOC a CARTA9.DOC, puedes usar este comando:
letra de directorio[0-9].doc
Puede encontrar todos los archivos que tengan una vocal como segunda letra en su nombre de esta manera. Este ejemplo también demuestra cómo mezclar los caracteres comodín:
dir?[aeiouy]*
Puede excluir un grupo de caracteres o un rango de caracteres usando un signo de exclamación [!] como primer carácter dentro de los corchetes. Este ejemplo muestra todos los nombres de archivos que tienen al menos 2 caracteres, excepto aquellos que tienen una vocal como segunda letra en sus nombres:
directorio ?[!aeiouy]*
El siguiente ejemplo, que selecciona archivos como AIP, BIPy TIP pero no PNI, demuestra cómo se pueden utilizar múltiples rangos dentro de los corchetes. Aceptará un archivo que comience con un A, B, C, D, T, Uo V:
directorio [a-dt-v]ip
Puede utilizar un carácter de signo de interrogación dentro de los corchetes, pero su significado es ligeramente diferente al de un comodín de signo de interrogación normal (sin corchetes). Un comodín de signo de interrogación normal coincide con cualquier carácter, pero se ignorará cuando coincida con un nombre más corto que la especificación del comodín, como se describe anteriormente. Un signo de interrogación entre corchetes coincidirá con cualquier carácter, pero no se descartará al buscar coincidencias con nombres de archivos más cortos. Por ejemplo:
letra del directorio[?].doc
mostrará CARTA1.DOC y LETRA.DOC, Pero no CARTA.DOC.
Puede repetir cualquiera de los caracteres comodín en cualquier combinación que desee dentro de un solo nombre de archivo. Por ejemplo, el siguiente comando enumera todos los archivos que tienen una A, Bo C como tercer carácter, seguido de cero o más caracteres adicionales, seguido de un D, Eo F, seguido opcionalmente de algunos caracteres adicionales y con una extensión que comienza con P or Q. Probablemente no necesites hacer nada tan complejo, pero lo hemos incluido para mostrarte la flexibilidad de los comodines extendidos:
directorio ??[abc]*[def]*.[pq]*
También puede utilizar la sintaxis comodín de corchetes para solucionar un conflicto entre nombres de archivos largos que contienen punto y coma [;], y el uso de un punto y coma para indicar una incluir lista. Por ejemplo, si tiene un archivo en una unidad LFN llamado C:\DATOS\LETRA1;V2 y escribes este comando:
del \datos\letra1;v2
no obtendrás los resultados que esperas. En lugar de eliminar el archivo nombrado, TCC intentará eliminar CARTA1 y luego V2, porque el punto y coma indica una incluir lista. Sin embargo, si utiliza corchetes alrededor del punto y coma, se interpretará como un carácter de nombre de archivo y no como un separador de lista de inclusión. Por ejemplo, este comando eliminaría el archivo mencionado anteriormente:
del \datos\letra1[;]v2
Coincidencia de nombres de archivos cortos (SFN)
Si la opción de configuración Buscar SFN está configurada, en TCC las búsquedas con comodines aceptan una coincidencia en el LFN or el SFN para que coincida con el comportamiento de CMD. Esto puede provocar que se encuentren algunos archivos debido a una coincidencia SFN únicamente. En la mayoría de las situaciones, esto no es realmente deseable y se puede evitar desactivando la opción (el valor por defecto).
Nota: El comodín El proceso de expansión intentará permitir que ambos CMD-Coincidencia de "extensión" de estilo (solo una extensión, al final de la palabra) y avanzada TCC coincidencia de nombre de archivo (permitiendo cosas como *.*.abc) cuando se encuentra un asterisco en el destino de un COPIA, MOVIMIENTO or REN / RENOMBRAR mando.
Comodines en nombres de directorios
TCC (pero no CMD) admite comodines en los nombres de los directorios (pero no en el nombre de la unidad), para uso interno. TCC comandos y funciones. Estos tipos de comodines son comunes en Linux, pero no son compatibles con CMD ni con la mayoría de las aplicaciones de Windows.
Puede controlar la recursividad del subdirectorio especificando * or ** en el camino. A * coincidirá con un único nivel de subdirectorio; a ** coincidirá con todos los niveles de subdirectorio para ese nombre de ruta. Los comodines de directorio también admiten expresiones regulares. Los comodines de directorio no se pueden utilizar con la opción /O:... (que ordena las entradas antes de ejecutar el comando). ¡Y piense con mucho cuidado antes de usar comodines de directorio con una opción /S (subdirectorios recursivos), ya que esto casi seguramente arrojará resultados inesperados!
Por ejemplo, para eliminar el archivo Foobar en cualquier subdirectorio de c:\test\test2 (pero no en ninguno de sus subdirectorios):
del c:\test\test2\*\foobar
Para eliminar el archivo Foobar en cualquier subdirectorio bajo c:\test (y todos sus subdirectorios) que tenga "foo" en cualquier parte del nombre:
del c:\test\**\*foo*\foobar
Para eliminar el archivo Foobar en cualquier subdirectorio de c:\test que comience con a t y termina con un 2:
del c:\prueba\t*2\foobar
Hay algunos comandos que no admiten comodines de directorio, ya que carecerían de sentido o serían destructivos (por ejemplo, TREE, @FILEOPEN, @FILEDATE, etc.).
Expresiones regulares de Windows en TCC
Además de extendido Comodines de Windows (*, ?, y [...]), TCC apoya el uso de comodines de expresión regular para hacer coincidir y reemplazar nombres de archivos en comandos internos de manejo de archivos (COPY, DEL, DIR, MOVE, REN, etc.). Puede elegir la sintaxis de expresión regular que desea utilizar: TCC admite expresiones regulares de Perl, Ruby, Java, grep, POSIX, gnu, Python y Emacs.
La sintaxis es:
::expresión regular
Por ejemplo:
directorio ::ca[td]
Tenga en cuenta que el uso Expresiones regulares de Windows ralentizará un poco las búsquedas en el directorio; dado que Windows no las admite de forma nativa, el TCC El analizador tiene que convertir el nombre del archivo a *, recupere todos los nombres de archivos y luego haga coincidirlos con la expresión regular.
Si tiene caracteres especiales (espacios en blanco, caracteres de redirección, caracteres de escape, etc.) en su expresión regular, deberá encerrarlos entre comillas dobles. Por ejemplo:
directorio "::^\w{1,8}\.btm$"
Para obtener más información sobre comodín de expresión regular sintaxis, ver Sintaxis de expresiones regulares existentes Take Command ayuda.
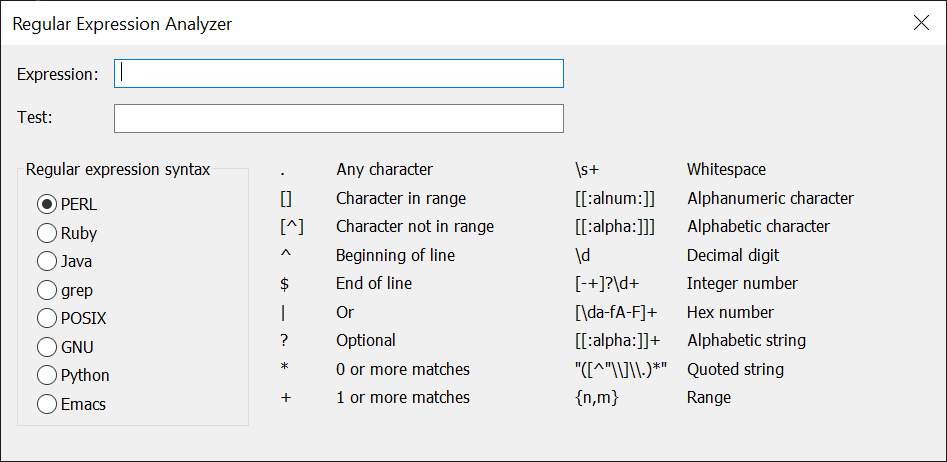
Para simplificar la creación y prueba de expresiones regulares, Ttomar el comando y TCC incluir un cuadro de diálogo del analizador de expresiones regulares (Ctrl-F7 desde el TCC línea de comando, o en el menú Herramientas en Take Command.) Hay dos cuadros de edición:
- La primera es para probar la expresión regular. Si la expresión regular es válida, el cuadro de diálogo mostrará una marca de verificación verde a la derecha del cuadro de edición de la expresión. Si la expresión regular no es válida, el cuadro de diálogo mostrará una X roja.
- El segundo cuadro de edición es para el texto que desea comparar con la expresión regular. Si el texto coincide con la expresión regular, el cuadro de diálogo mostrará una marca de verificación verde a la derecha del cuadro de edición de prueba. Si el texto no coincide, el cuadro de diálogo mostrará una X roja.